Tavily and OpenClaw
Tavily is now natively integrated into OpenClaw, giving agents built-in access to real-time search and structured results without any additional setup.

Tavily is now a native integration in OpenClaw. Agents can call Tavily directly for up-to-date information and structured results. No additional setup required, no interruption to execution.
If you haven't used OpenClaw yet, it's one of the first agent frameworks that runs locally with persistent context and continuous operation. It gives agents a full execution loop: plan tasks, write and run code, call tools, and iterate until they reach a result. Instead of prompting a model once, you're defining systems that can take actions.
Why Choose Tavily As Your Native Search In OpenClaw?
Agents need access to current and accurate information or they fail in very predictable ways. They either stall when they hit something they don’t know or confidently produce answers that are outdated, incomplete, or just wrong.
A lot of setups try to fix this by layering retrieval on top. In practice, that usually means raw HTML, inconsistent formatting, and a bunch of cleanup logic that can become your problem fast.
More noise in → worse reasoning out.
Tavily is built specifically for AI consumption, not humans.
We optimize for efficiency per token: delivering higher factual accuracy, relevance, and coverage with fewer tokens. This goes beyond cost optimization, it directly improves end-user latency and model performance.
An agent sends a natural language query and gets back ranked, relevant, structured results consistently formatted and immediately usable. That alone removes a surprising amount of friction.
OpenClaw already handles the rest well. Agents know when to call a tool, how to pass inputs, and how to use outputs in the next step. Tavily just fits into that pattern.
So the loop becomes simple: plan → realize you need information → call search → continue.
Get Started Building
At this point the kinds of tasks you give an agent change. You stop asking one-off questions and start asking it to explore:
- Compare multiple APIs based on recent developer feedback.
- Track how a company’s positioning has changed over time.
- Find and summarize the latest releases from competitors.
The agent searches more than once, refines its queries, and builds an answer step by step. Retrieval stops being a single step and becomes part of the reasoning. If you try this with something real (not a toy prompt), you’ll notice it quickly. The agent doesn’t get stuck dealing with messy results. It just uses them and moves on.
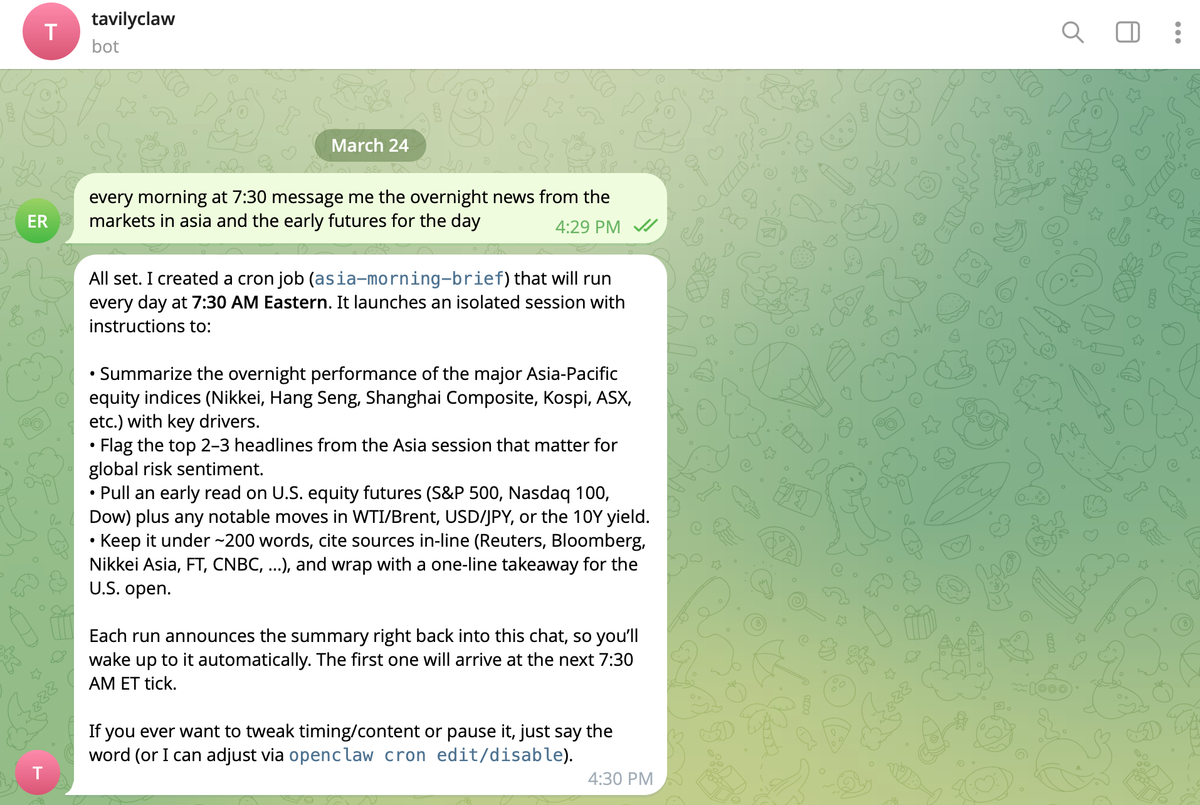
Take a task like:
“Compare three AI coding assistants based on recent developer feedback and pricing.”
With a generic search setup, the agent often needs multiple passes, one to return broad results, a second to refine the query, and then additional steps to clean and extract usable content.
With Tavily, the first response is already filtered and structured around the query. The agent spends less time refining retrieval and more time synthesizing results.
In practice, that means:
- Fewer search calls per task
- Less token usage per step
- Faster end-to-end execution
Search sits at the center of the loop. Small inefficiencies there multiply quickly.
Tavily is optimized specifically for AI retrieval, relevance, structure, and efficiency at the token level. That shows up fast once your agent starts making multiple calls and chaining results together.
Search touches everything else in the system. It’s not something where you want “good enough.”
Now you need to get started building and giving agents more ambitious tasks:
- “Track how this company’s positioning has changed over the last year”
- “Compare three competing APIs based on recent developer feedback”
- “Find and summarize the latest releases from your competitors”
The agent explores, searches, revises, and builds an answer iteratively. You stop thinking in terms of single queries and start thinking in terms of information-seeking behavior.
If you’re already using OpenClaw, this is one of those integrations you can feel immediately. Give your agent a task that requires real-world knowledge. Watch when it reaches for search. Inspect what comes back. See how it uses it.
Then try pushing it a bit further.
Ask a harder question. Add constraints. Force it to compare, synthesize, and justify. That’s where the combination starts to show its shape. Agents don’t need more prompts, they need better tools and search is one of the most fundamental ones. Now it’s part of the loop. Try it out and let us know what you think.