
/engineering4 min read
How we built the fastest web search in the world
Speed matters when every millisecond counts. Tavily’s Fast and Ultra-Fast search depths deliver sub-second results without sacrificing relevance, maximizing information density with fewer tokens. Built for real-time agents, voice interfaces, and latency-critical workflows, Tavily redefines search efficiency.
Speed kills in latency critical applications. Voice interfaces break when pauses exceed a second. Financial trading agents live or die by their ability to ingest market data before prices move. Even a 1-2 seconds search delay compounds rapidly across tool calls and follow up queries.
That’s why Tavily built Fast and Ultra Fast search depths, to minimize latency without sacrificing document relevance, allowing developers to choose their optimal position on the latency relevance curve. When accuracy matters more than raw speed, Tavily Research delivers SOTA results, ranking #1 on the DeepResearch Bench.
To quantify these tradeoffs, we evaluate Tavily’s performance across benchmarks that measure both latency and accuracy under real world query conditions.
Benchmarks
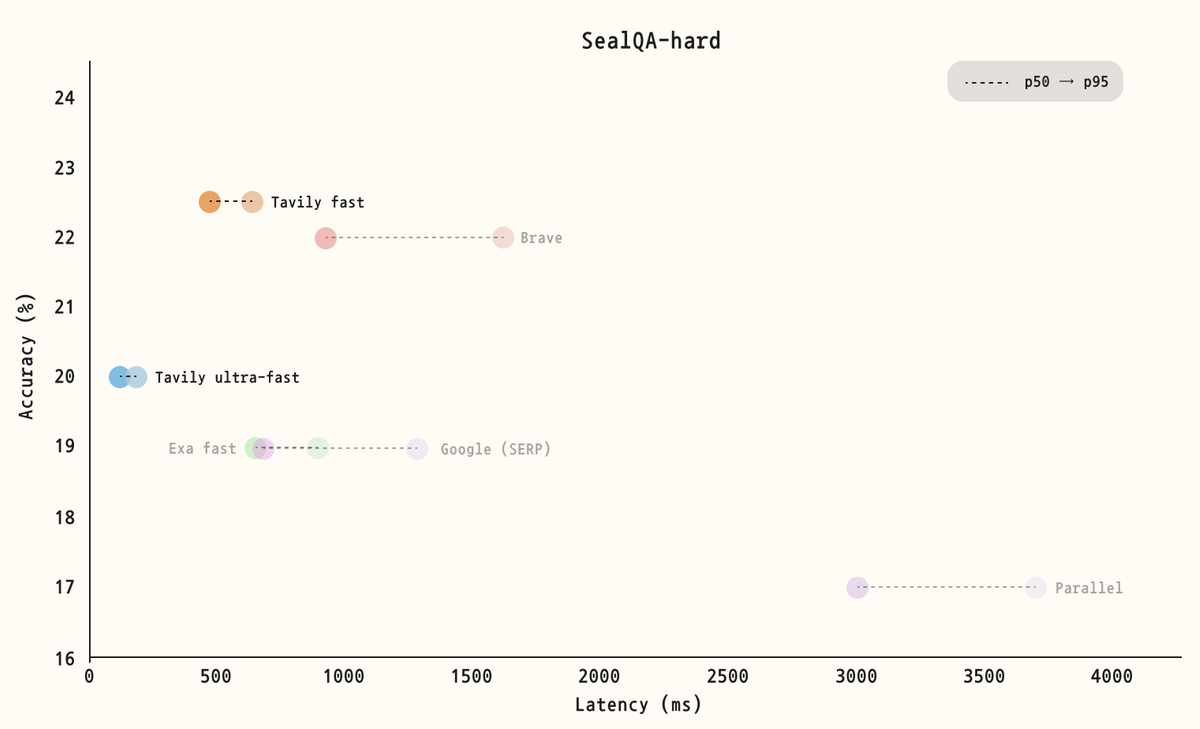
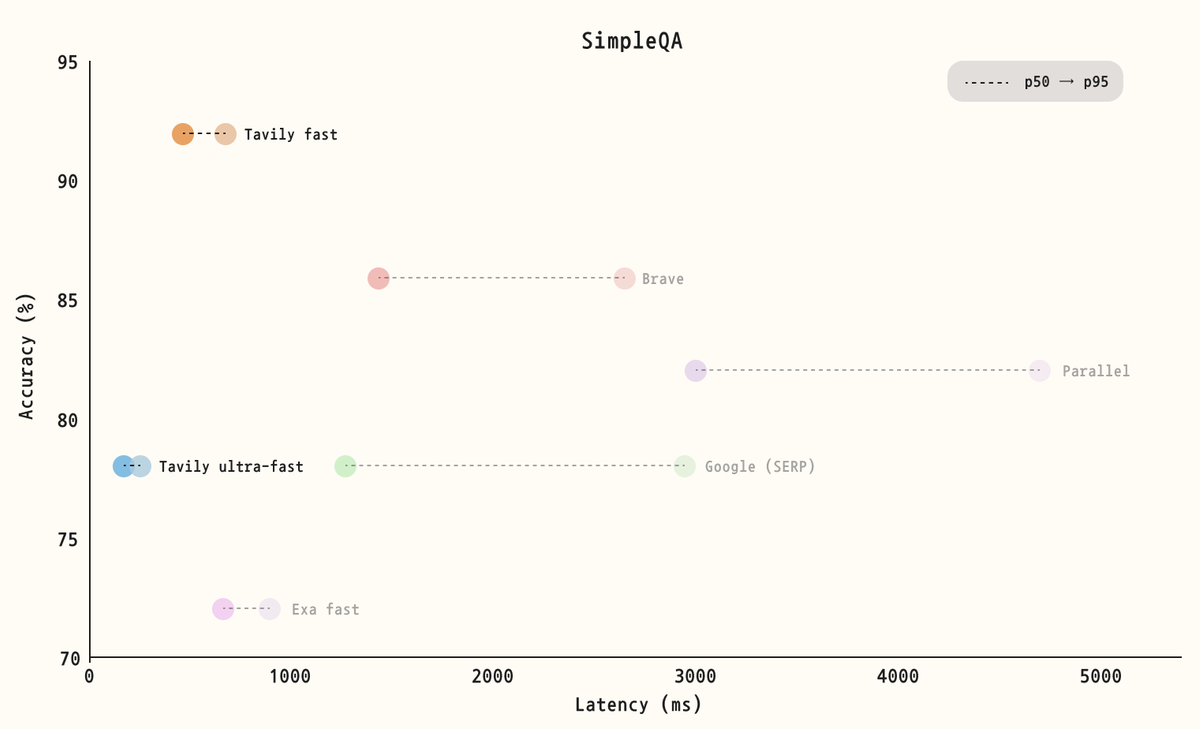
These benchmarks evaluate Tavily’s latency and accuracy across both challenging multi-step reasoning questions (SealQA-hard) and straightforward fact-seeking queries (SimpleQA).
Together, the results demonstrate the exceptional speeds Tavily achieves while maintaining high document relevance. In the next section, we expand on our vision and explain why document relevance is critical to achieving both speed and quality.
To ensure a fair comparison, we standardized output token lengths across providers whenever possible. For providers that do not allow explicit control over output length, we used their default configurations. Each benchmark was run twice per provider, and the reported results represent the average scores.
Efficiency as a First-Class Metric
Speed alone is an incomplete story.
At Tavily, efficiency is a guiding principle in how we design and ship search infrastructure. When we talk about efficiency, we don’t mean raw latency, we mean how much useful work can be done per millisecond. In other words, not just “how fast” a request completes, but how much value it delivers in that time.
We like to think of this as Information Density per millisecond,the amount of high-quality, decision-ready information produced per millisecond.
This mindset fundamentally changes how a search API should be evaluated. A system that responds quickly but returns noisy, redundant, or low signal results pushes the real cost downstream, onto developers, applications, and LLMs. True efficiency means minimizing total compute, reasoning, and latency across the entire pipeline.
Efficiency per Token: Optimizing for LLM Reality
For agentic applications, efficiency has a second, equally critical dimension, tokens.
Every extra token sent to an LLM increases:
- inference latency
- compute cost
- context window pressure
- and often, reasoning noise
That’s why we optimize for efficiency per token: delivering higher factual accuracy, relevance, and coverage with fewer tokens. This is not just a cost optimization, it directly improves end-user latency and model performance.
By returning tightly scoped, high signal search results, Tavily reduces:
- the number of tokens the LLM needs to read
- the time the LLM spends reasoning
- and the likelihood of hallucination or over-reasoning
This creates a compounding latency win:
- Faster search execution
- Smaller, cleaner inputs to the LLM
- Faster LLM responses
Search efficiency and LLM efficiency reinforce each other.
Designing for End-to-End Efficiency
Our goal is not to win micro benchmarks in isolation, it’s to maximize end-to-end system efficiency for modern AI applications. From crawl selection, ranking, and synthesis to output structure, every design choice is guided by a single question:
Does this increase the Information Density per millisecond we deliver?
That philosophy is what enables Tavily to feel fast not just at the API level, but at the application level … where it actually matters.
How to + Use-cases
To support a wide range of agentic applications, Tavily provides configurable parameters that let you tailor search behavior to your requirements.
Start by selecting the appropriate search_depth in the Tavily Search tool. This parameter allows you to explicitly choose your position on the latency–relevance curve. To try the fast and ultra-fast modes, set the search_depth = "fast" or "ultra-fast" .
## First install the Tavily Python SDK
# pip install tavily-python
from tavily import TavilyClient
tavily_client = TavilyClient(api_key="tvly-YOUR_API_KEY")
response = tavily_client.search(query="Who is Leo Messi?", search_depth="fast")
print(response)
When search latency directly impacts your user experience, Tavily's fast modes become critical. Deploy them for:
- Voice agents where every 1000ms of "tool-calling" time degrades user experience
- High-frequency trading agents that need market context before prices shift
- Interactive coding assistants fetching the latest package updates without breaking developer flow
- Chat bots that needs to feel responsive while maintaining quality
Conclusion
AI agents are approaching human level interaction speeds, not only in conversation, but across every interface where users expect instant responses.
Tavily is building search infrastructure designed for this reality, sub second latency, high information density per millisecond, and relevance that compounds efficiency across the entire agent stack. fast and ultra-fast search depths are the first step toward enabling real time, multi hop agent workflows at scale, without sacrificing quality.